Most of the time, Web browsers only provide mouse and keyboard inputs.
These solutions are not so efficient for people with some handicap like arms paralysis.
So it could be interesting to provide other inputs like voice and/or eye tracking.
These extra inputs could be useful even for normal people,
in situations when it is not convenient to use mouse or keyboard,
like when cooking and following a recipe on the Internet.
This project is a secondary and more personal work, during my traineeship in Risø.
It has started by an advanced study of Internet standards (XHTML, CSS, etc.), which can be used,
and ergonomics considerations like the list of spoken commands that are useful.
In addition to the very common mouse and keyboard,
different input systems could be used to browse the Internet;
voice and eye-tracking have been studied here.
A voice input system allows the user to say a limited amount of standard commands like "next, previous, first, last, home, up, find, help, etc." to activate the corresponding page - if available -, or to do some more classic actions like scrolling the page, activating links, navigating to the previous page, etc...
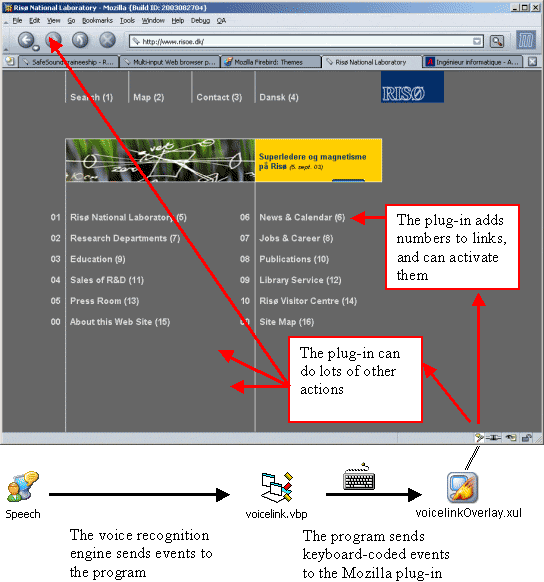
The system developed here is based on a voice recognition program (using Microsoft Speech SDK 5.1) that sends keyboard events to a plug-in (integrated into the Web browser Mozilla), which does the corresponding actions.
For standardised navigation feature to be used,
Web pages have to respect some standard accessibility recommendations.
In particular, pages will have to use the LINK tag to specify standard links like "next, previous, first, etc.".
This tag is included in HTML specification since HTML 2.0,
is still present in the current XHTML 1.1 and its utilisation is very encouraged.
This subject is developed in my documentation about META information in HTML Web pages.
Example:
<LINK rel="start" href="../../index.en.html" />
Currently, some browsers (Mozilla, Opera, etc.) use that kind of standard links, which can be activated thanks to a navigation bar.
A speech recognition engine based on a limited dictionary allows very high recognition accuracy,
even without any learning process, providing any user a good usability.
In the case of this project, there are only about thirty commands that are to be recognised here.
Microsoft Speech SDK 5.1 has been chosen since
it is easy to deploy and convenient for the final user.
The voice program has been developed in Visual Basic since other programs with voice recognition
had already been developed like that for the main subject of my traineeship.
The recognition program is based on a
Microsoft Sapi 5.0 SR Command and Control grammar,
which specifies all the possible commands that could be recognised.
Here is an extract of this grammar:
voicelink.xml
<GRAMMAR LANGID="409"><!-- xml:lang="en-US" -->
<RULE NAME="voicelink" TOPLEVEL="ACTIVE">
<PHRASE>
<PHRASE>computer</PHRASE><!-- introduction word -->
<OPT>...</OPT>
<LIST>
<PHRASE><!-- scroll -->
<LIST>
<PHRASE>scroll</PHRASE>
<PHRASE>page</PHRASE>
</LIST>
<LIST>
<LIST PROPNAME="{PGDN}">
<PHRASE>down</PHRASE>
</LIST>
<LIST PROPNAME="{PGUP}">
<PHRASE>up</PHRASE>
</LIST>
<LIST PROPNAME="{END}">
<PHRASE>bottom</PHRASE>
</LIST>
<LIST PROPNAME="{HOME}">
<PHRASE>top</PHRASE>
</LIST>
<LIST PROPNAME="{DOWN}">
<PHRASE>step down</PHRASE>
</LIST>
<LIST PROPNAME="{DOWN}">
<PHRASE>step up</PHRASE>
</LIST>
</LIST>
</PHRASE>
<!-- more code here -->
</LIST>
</PHRASE>
</RULE>
</GRAMMAR>
For each command, the PROPNAME attribute contains the value (token)
that will be used by the recognition program, which will react consequently.
The grammar is very constraint, most of the time there is only one sentence that can be used for a specific action.
Here are some sentences that can be recognized, and their meaning:
The following commands generate events like if it was done by the keyboard:
- computer scroll down
- Scroll the window one page down
- computer scroll up
- Scroll the window one page up
- computer scroll bottom
- Scroll to the bottom of the page
- computer scroll top
- Scroll to the top of the page
- computer scroll step down
- Scroll the window 3 lines down
- computer scroll step up
- Scroll the window 3 lines up
- computer go backward
- Navigate to the previous visited page (same as "back" button)
- computer go forward
- Navigate to the next visited page (same as "forward" button)
The following commands are only available on Web pages respecting accessibility rules using the LINK tag:
- computer go home
- Navigate to home page of the Web site
- computer go up
- Navigate to the parent page
- computer go first
- Navigate to the first page in a list of documents
- computer go previous
- Navigate to the previous page in a list of documents
- computer go next
- Navigate to the next page in a list of documents
- computer go last
- Navigate to the last page in a list of documents
- computer go table of content
- Navigate to the table of content
- computer go glossary
- Navigate to the glossary
- computer go index
- Navigate to the index
- computer go help
- Navigate to the help page
- computer go search
- Navigate to the search page
- computer go author
- Navigate to the author page
- computer go copyright
- Navigate to the copyright page
This last set of commands deals with hyperlink navigation:
- computer set display links on
- Display links numbers (enabled by default)
- computer set display links off
- Hide links numbers
- computer go link two three
- (example) Navigate to the 23rd link
The voice recognition program has not been integrated into the Web browser, and has to be executed separately.
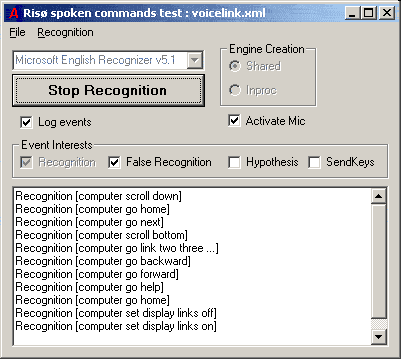
Main window of the voice recognition program.
The user just has to click on the main start button then minimise the window.
Indeed, the program tries to load the grammar from the file voicelink.xml
that should be in the same directory; another grammar can be loaded if needed.
Some feedback on different events can be provided for testing in the main window,
like in this example.
Here is an extract of the code of the voice recognition program.
It is the code that is executed when a good recognition has been made by the voice recognition engine.
voicelink.frm 'When a recognition event is launched by the voice recognition engine Private Sub RC_Recognition(ByVal StreamNumber As Long, ByVal StreamPosition As Variant, ByVal RecognitionType As SpeechLib.SpeechRecognitionType, ByVal Result As SpeechLib.ISpeechRecoResult) Dim RecoNode As Node Dim Prop As ISpeechPhraseProperty Dim Properties As ISpeechPhraseProperties Dim myString As String myString = "" 'keyboard sequence that will be sent to the Web browser Set Properties = Result.PhraseInfo.Properties If Not Properties Is Nothing Then If Properties.Count > 0 Then 'get PROPNAME properties from the grammar For Each Prop In Properties If Not Prop Is Nothing Then myString = myString & Prop.Name End If Next SendKeys myString 'Simulate a keyboard event End If End If 'More code here End Sub
In a second time, an eye tracking system will be added to this multi-modal browser.
When these words were written, data extraction from an eye tracking system was being studying.
It could be used mainly to provide a scrolling function in Web pages.
The browser could scroll the Web page according to the eye position.
Moreover, that kind of eye tracking does not require such a good precision,
and could provide an intelligent and pleasant reaction.
Nevertheless, it is possible to imagine a spoken command to turn on and off this feature,
which can be annoying sometime.
If the first goal is achieved, eye tracking could be used to activate normal hyperlinks on the Web page. But this requires more precision, so also a more complicated and/or invasive hardware.
Developing a Web browser is long and heavy.
Also the idea for this project is to build a plug-in that can be integrated into an existing Web browser.
The choice has been made on Mozilla, since it is one of the best current Web browsers,
very dynamic, up-to-date and last but not the least: open-source.
Netscape and other browsers are also based on Mozilla.
The XML-based User Interface Language (Xul)
has been used to develop a plug-in for Mozilla that receives orders from the voice recognition and eye tracking programs.
This technology uses Internet standards like XML,
CSS2, JavaScript, RDF.
Once a Xul plug-in has been installed once, it is loaded at start-up, exactly like other functionalities of Mozilla.
Here is the main XML file, which is adding an icon into the status bar in the bottom right of Mozilla.
voicelinkOverlay.xul <?xml version="1.0" encoding="ISO-8859-1"?> <?xml-stylesheet href="chrome://voicelink/content/voicelink.css" type="text/css"?> <overlay id="voicelinkOverlay" xmlns="http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul"> <script type="application/x-javascript" src="chrome://voicelink/content/voicelink.js" /> <statusbar id="status-bar"> <statusbarpanel class="statusbarpanel-iconic" id="risoespeech" insertbefore="offline-status" onclick="voiceLinkClick()" status="off" tooltiptext="Risoe speech command - Disabled" /> </statusbar> </overlay>
A CSS2 file is used for style matters, exactly as if it was for a Web page. Here is the whole file:
voicelink.css
statusbarpanel#risoespeech {
list-style-image:url("chrome://voicelink/content/voicelink_off.gif");
}
statusbarpanel#risoespeech[status="off"] {
list-style-image:url("chrome://voicelink/content/voicelink_off.gif");
}
statusbarpanel#risoespeech[status="on"] {
list-style-image:url("chrome://voicelink/content/voicelink_on.gif");
}
statusbarpanel#risoespeech[status="wait"] {
list-style-image:url("chrome://voicelink/content/voicelink_wait.gif");
}
The programming language is JavaScript, and the code is stored in a separated file. It is possible to intercept events, interact with all the functions of Mozilla, access and modify the current Web document. Here is a short extract of this file:
voicelink.js
var contentArea=document.getElementById("appcontent");
contentArea.addEventListener("unload",voiceLinkUnload,true);
contentArea.addEventListener("load",voiceLinkLoad,true);
function voiceLinkUnload()
{
isActive=false;
isLinksNumber=false;
updateVoiceLinkState();
}
function voiceLinkLoad()
{
isActive=true;
updateVoiceLinkState();
if (wantsActive && wantsLinksNumber) displayLinksNumber();
}
//More code here
Orders are transmitted from the voice recognition program to the browser plug-in through the keyboard. This allows events to be managed by the user interface. With this solution, there is no need to create any other special dialog.
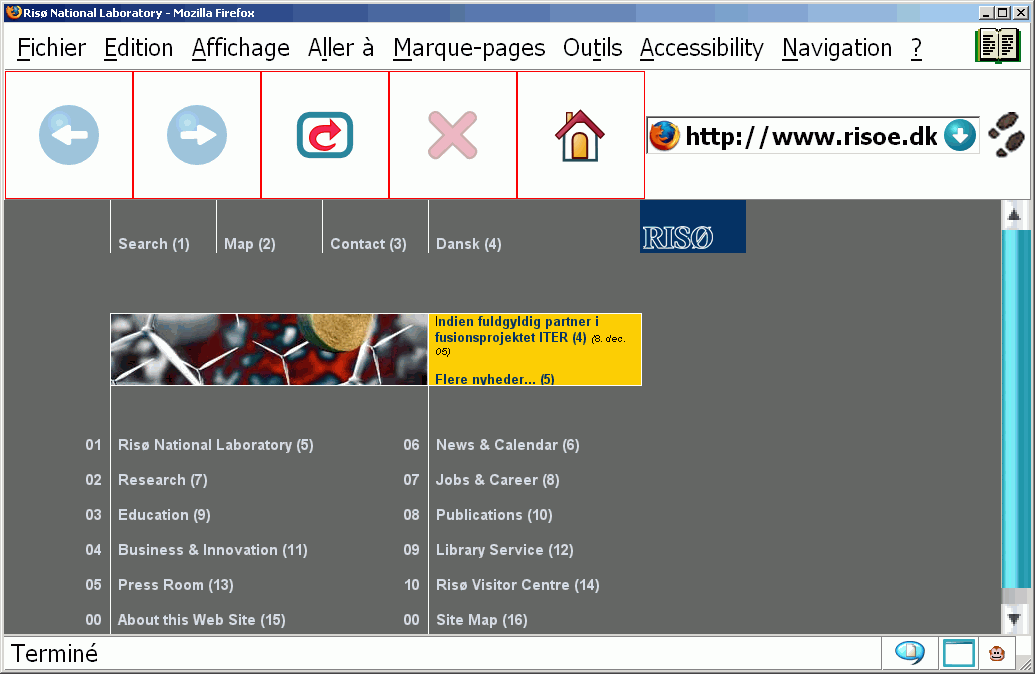
In order for the user to be able to activate links by voice, it seems to be a good idea to give a number to each link.
This has been done, and the user can chose to have after each links, its number in parenthesis.
Example: This is an example with a first link (1) and another one (2).
This works in any valid HTML page that respects standards for accessibility:
i.e. it is not working on links using pictures and/or javascript.
If this project is successful and if it appears to be interesting at a larger scale, it could be possible to go on developing it, and to provide support for other browsers like Microsoft Internet Explorer.
Also, this project could be used to test how several modes (voice, gestures) can be used at the same time.