Université Paul Sabatier Toulouse III
DESS (Postgraduate Diploma) in
artificial Intelligence, pattern Recognition, Robotics
(IRR)
TRAINING COURSE SUMMARY
for
Risø National Laboratory
from April 2003 to September 2003
by
Alexandre Alapetite
Training course directors:
| Université Paul Sabatier | | Risø |
|---|
DESS IRR
LAAS-CNRS
7 Avenue du Colonel Roche
31077 Toulouse cedex 4
FRANCE
|
|
Risø National Laboratory
Systems Analysis Department
Building SYS-110, P.O.Box 49
Frederiksborgvej 399
DK-4000 Roskilde
DENMARK
|
| UPS access map |
|
Risø SYS access map |
Abstract
This document describes my work during a traineeship in the systems analysis department of Risø,
a Danish national laboratory.
My primary mission was to develop some programs that were aimed to demonstrate how pilots could use voice commands
to control some devices in aircrafts.
For that, I have had to study different voice engines solutions and grammar languages.
Since this primary project left me some free time, I have done a secondary and more personal project
which consisted in studying Web pages accessibility standards,
and providing a system that allows voice input commands in a Web browser.
You can have a look to the
French translation of this abstrac
and its Powerpoint presentation.
Acknowledgements
I wish to thank people without who this training course would not have been possible.
Since I have to choose an order for acknowledgements,
I will do it temporally from the beginning to the end of this story.
It begins in the University Paul Sabatier of Toulouse,
where I wish to thank my English teacher Suzan Becker who was the only one that helped me
with administrative matters to do this traineeship abroad.
Michel Courdesses has to be congratulated for the difficult planning of the end of the DESS
just before the beginning of traineeships, and for the time he spends for everything to work,
especially with administrative papers.
I am thankful to Régine André-Obrecht for having accepted to be my training course director in France,
helped by Jérôme Farinas.
Then I arrived in Denmark. People from the whole department of system analysis have been very friendly and helpful;
that have made my arrival and these six months so nice:
everything was made for me to feel well.
I am very grateful to Hans Andersen for having accepted me for this traineeship, followed my work,
kept me involved in the activity of the department − like meetings − and much more.
Special thanks to Steen Weber, with whom I have worked for most of the things that have been produced
during this traineeship: he always got time for me when needed, like for the writing of this report.
Table of contents
Exit
Integration
Risø is a Danish national laboratory.
It was founded in 1956 for "a peaceful utilisation of nuclear power".
But in 1985 it was decided to stop research related to nuclear power.
Now, Risø has several centres, as different as "Human-Machine Interaction",
"Plant-Microbe Basic Research", "Fusion Research", "Wind Energy", etc.
I have worked for the "Systems Analysis" Department,
which research is orientated mainly on strategies in relation to long-term energy development,
safety, reliability and decision-support in the industry.
This department, composed of a cross-disciplinary staff of about 70,
is divided into four research programmes;
I have been involved into the "Safety, Reliability and Human Factors" one,
which aim is to develop methods to analyse the safety and reliability of complex technical systems
and within which about 20 scientists, psychologists and information specialists co-operate.
So I was, in this department, one of the few IT specialists. That has made our work complementary and rich.
A lot is made in Risø in order to keep employees satisfied and motivated.
This is based, for example, on interesting jobs, innovation, cooperation, international contacts
but also social events, tolerance which are essential for integration:
As a result, I have quickly felt good in Risø.
Since about 10% of employees do not speak Danish natively, Risø has permanent Danish courses.
I have followed them for more than two months before summer holidays and again from September.
Thanks to that, I am already able to have small private conversations;
most of the professional conversations and documents being in English anyway.
Risø from a plane

Introduction
My primary mission was to participate into the Safesound project,
a European project on Safety improvement by means of sound,
part of the Growth
priority of the Cordis fifth framework programme
(reference [G4RD-CT-2002-00640], May 2002 to December 2005).
The goal of the Safesound project is to study how an audio system (speech recognition and synthesis) could be integrated into
plane cockpits and air traffic management systems for safety critical operations.
Different points are studied, like human factors in audio interaction,
the physical installation in cockpits and its impact on procedures and finally the resulting safety benefits.
Most of the necessary technologies (like voice recognition) already exist but they have to be adapted
to safety critical domains in order to be used in plane cockpits.
Risø and different other companies are working together
in an international consortium financed by the European Commission:
EADS Airbus (FR),
Thales avionics (FR),
Eurocontrol (FR),
Alitalia team (IT),
AKG acoustics (AU),
NLR Netherlands National Aerospace Laboratory (NL),
TNO Netherlands Organisation for Applied Scientific Research (NL).
Risø is responsible for studying human factors, like analysing crew tasks,
developing and analysing prototypes that will reveal human-system performance
in both normal and abnormal flight conditions.
I have been charged to design and build those prototypes,
and helped in statistical analysis of human-system differences between normal and abnormal flight conditions.
Plane cockpit
When I arrived, my department in Risø did not have much experience of voice recognition, and no voice recognition system.
An evaluation version of Nuance had been promised by TNO before I arrived, but we received it in June.
So, in order to build some prototypes and not to loose time,
I have had to find and test some speech tools, then to choose one from them.
My policy had been to first try systems I knew already, then systems for which a trial version was available on the Internet.
Microsoft Agent
Introduction
 Microsoft® Agent
Microsoft® Agent
is a software technology that supports interactive animated 3D characters that can respond to
mouse, keyboard, voice input, and that are able to speak, move, display text.
This is based on ActiveX technology,
so it is possible to use and program Microsoft Agent with several ways like
- from a Web page (with VBScript or JavaScript) for Internet browsers
on Microsoft Windows platform (Internet Explorer 4 and more)
- from any other language that support ActiveX
like Borland Delphi,
Visual Basic, Visual C++, .NET, ...
Installation
Some software has to be installed on the client side;
some of them can be downloaded automatically if they are not already installed on the computer,
thanks to a <OBJECT> tag,
but there are still needed components that have to be downloaded and installed once
from the Microsoft webpage.
The most important components are:
- Microsoft Agent Control
- a Text-to-Speech (TTS) output. The one provided by Microsoft is from Lernout&Hauspie
and is available for several languages
- a speech recognition engine
Sapi 4.0 compatible.
The one provided by Microsoft is only for US English [en-US].

In the control panel, there is a "Speech" icon with a microphone.
Once these components installed, you can see them in here.
Programming
Programming speech recognition with Microsoft Agent is fast and easy.
The system is based on context-free grammars.
msAgent.Commands.Add "Work", "Say your work", _
"(say your work | who are you working for | what do you do)", True, True
This peace of code enable the agent to recognize the commands "say your work",
"who are you working for" or "what do you do" and in both cases will return the token "Work" to the program.
Then the token can be intercepted and treated into the program:
Sub AgentControl_Command(byVal UserInput)
Select Case UserInput.Name
Case "Hello"
SayHello
Case "Work"
SayWork
End Select
End Sub
Sub SayWork
msAgent.Play "Blink"
msAgent.Speak "I work for Risoe!|I am a virtual employee of Risoe"
msAgent.Play "RestPose"
End Sub
Here we can see that the agent will answer randomly "I work for Risoe!" or "I am a virtual employee of Risoe"
when it recognizes a question about its work.
"Blink" is just for some graphic animation; indeed, Microsoft Agent characters
are able to do animations like shaking head, showing, walking, even express some basic feelings.
You can test it online here or from
Microsoft's website
Conclusion
In my opinion, Microsoft Agent is a powerful tool to enhance human-computer interaction,
thanks to its ability to use keyboard, mouse and voice inputs, and text, sounds, animations and voice outputs.
The default Text-To-Speech provided by Microsoft is understandable, but far from the best systems available at this time.
The default speech recognition engine (US English [en-US] only) is quite efficient, as far as the microphone is good enough.
It is possible and could be a good idea to buy Text-To-Speech and/or
speech recognition Sapi 4.0 compatibles
from third party companies that can be used in place of the defaults ones.
As drawbacks, this system will not be a good choice if planning to use context-dependant grammars,
or interact with speech recognition and speech synthesis at a lower level.
Furthermore, when these words were written,
Microsoft was moving its standards to Sapi 5.1 (providing mouth movement synchronization, etc.),
with which Microsoft Agent is unfortunately
not compatible, at least for now.
VoiceXML
Introduction
The Voice Extensible Markup Language is designed for creating audio dialogs
that feature synthesized speech, digitized audio, recognition of spoken and DTMF (telephone) key input,
recording of spoken input, telephony, and mixed initiative conversations.
Its major goal is to bring the advantages of web-based development and content delivery
to interactive voice response applications.
(from W3C).
At this time, voiceXML is at version 2.0 (02/2003),
but I have had the opportunity to test
version 1.0 (05/2000) with the free
IBM voice server SDK 3.1.
Installation
To program voiceXML pages and to launch the voice server,
I have used a demo version of
IBM WebSphere Studio Application Developer 5.0,
and it's Voice Toolkit 4.1.
All these installation files are 1GB to download.
Programming
VoiceXML pages also have to respect
XML 1.0 (10/1998, 10/2000) specifications.
Here is my first test, which allows the user to say several times a direction ("north", "south", "east", "west")
that is analyzed by the recognition system, until the user says "stop".
test1.vxml
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE vxml PUBLIC "vxml" "">
<vxml version="1.0">
<!-- Speed of recognition versus accuracy -->
<property name="speedvsaccuracy" value="0.9"/>
<!-- Level of confidence to accept a recognition -->
<property name="confidencelevel" value="0.5"/>
<!-- Disable barge in -->
<property name="bargein" value="false"/>
<!-- Time out after a possible recognition -->
<property name="completetimeout" value="1000ms"/>
<!-- Time out without any possible recognition -->
<property name="incompletetimeout" value="2000ms"/>
<!-- Constant messages -->
<var name="helpmessage" expr="'Please say go north, go south, go east, go west or stop.'"/>
<var name="exitmessage" expr="'The system will shut down now.'"/>
<form id="intro"><!-- main rule -->
<block>
Welcome to voice test
<goto next="#testDirection1"/><!-- Call rule "testDirection1" -->
</block>
</form>
<form id="testDirection1"><!-- rule "testDirection1" -->
<field name="goDirection">
<prompt>Where do you want to go?</prompt>
<grammar><!-- Inline grammar -->
go north {north}
| go south {south}
| go east {east}
| go west {west}
| stop [now] {stop}
</grammar>
<!-- If the user asks for help -->
<help><value expr="helpmessage"/></help>
<!-- 1st time the user says something no recognised -->
<nomatch>Direction?</nomatch>
<!-- 2nd time the user says something no recognised -->
<nomatch count="2">
<value expr="helpmessage"/><!-- read the constant message "helpmessage" -->
<clear/><!-- clear variables and start the rule again -->
</nomatch>
<!-- 3rd time the user says something no recognised -->
<nomatch count="3">
I did not understand.
<value expr="helpmessage"/>
</nomatch>
<!-- 4th time the user says something no recognised -->
<nomatch count="4">
Unfortunately, I still did not understand.
<value expr="exitmessage"/>
<exit/>
</nomatch>
<!-- 1st time the user did not say anything -->
<noinput>
I did not hear anything.
<value expr="helpmessage"/>
</noinput>
<!-- 2nd time the user did not say anything -->
<noinput count="2">
I did not hear anything.
<value expr="exitmessage"/>
<exit/>
</noinput>
<filled><!-- recognition -->
<if cond="goDirection=='stop'">
<value expr="exitmessage"/>
<exit/>
<else/>
I go to the <value expr="goDirection"/>.
</if>
<clear/><!-- clear variables and start the rule again -->
</filled>
</field>
</form>
</vxml>
This language allows context-free grammars programming.
It allows barge in (the user can talk while the system is speaking), and timeout control.
We have made some tests with this system to measure the best time out that could be used at the end of a sentence
to know that this sentence is over.
Conclusion
VoiceXML will certainly become the voice standard on the Internet and telephone voice servers.
Developing a voice service is fast, easy and clean.
Moreover, VoiceXML can use Internet standard protocols
and interact with other Internet programming languages like PHP,
to become even more powerful.
Indeed, VoiceXML pages can be dynamically generated, by PHP for example,
to be adapted to the context, access databases, store client information, etc.
But IBM WebSphere, which we use to execute VoiceXML files, is very expensive and too heavy for small distributable programs,
since it is more telephony orientated.
Microsoft Speech SDK 5.1
Introduction
The Microsoft Speech SDK 5.1
is a development kit that can be used from several programming languages.
It offers solutions for voice recognition (commands, dictation), voice synthesis,
and other things like mouth animation, etc.
You can now use the Win32 Speech Api (Sapi) to develop speech applications with Visual Basic,
ECMAScript and other Automation languages.
The SDK also includes freely distributable text-to-speech (TTS) engines (in U.S. English and Simplified Chinese)
and speech recognition (SR) engines (in U.S. English, Simplified Chinese, and Japanese).
(from Microsoft Speech Technologies).
The Microsoft Speech SDK 5.1 is not the latest version.
When these words were written, the latest was the Speech SDK 2.0 .NET,
which is more orientated on .NET projects.
Installation
This SDK can be installed
on Microsoft Windows 98, Me, NT4 6a, 2000, XP or later
with Internet Explorer 5.5 or later.
Then any compiler can be used but are specially recommended
Microsoft Visual Studio 6.0 SP3+
or Microsoft Visual Studio .NET.
In the control panel, there is a "Speech" icon with a man and a computer.
In this area, it is possible to train voice profiles, and choose a voice recognition engine.
The two next pictures come from buttons [Settings...] and [Train Profile...].
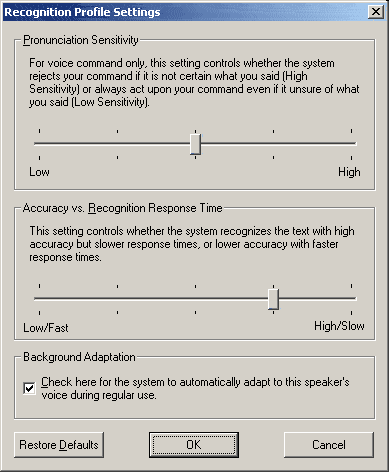
In this window, it is possible to set the sensitivity and the precision of the voice recognition engine,
for one profile.
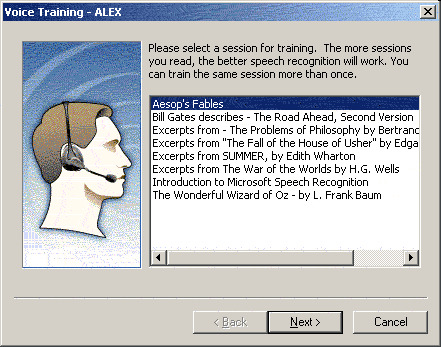
That is how a voice profile can be trained.
The user just has to select a text then to read it aloud.
Programming
I am using the commands recognition part of the SDK.
Like for VoiceXML, a XML file is used.
But unlike VoiceXML, this XML file is just for commands recognition,
and the main part of the recognition program is done in another language.
Unlike Microsoft Agent,
it is possible to program the voice recognition engine more freely,
it is not necessary to keep having an 3D agent character on the screen,
and the user do not have to press any key to switch on the voice recognition.
Once the grammar loaded, the program receives events from the speech recognition engine,
with lots of information that allows the production of the corresponding response.
Since the goal is to provide voice interaction to some existing
Visual Basic project,
I am using Visual Studio 6.0 SP5.
This has been facilitated by the demos provided in the SDK.
Grammars
Sapi 5.0 SR Command and Control grammar format is based on the
XML framework
but is not fully compliant with the
W3C Speech Recognition Grammar Specification.
Next versions of Sapi will be compliant with W3C.
Some description of the Sapi 5.0 grammar is provided with the SDK,
and on Microsoft MSDN,
but I will quickly describe anyway what I have used.
Grammars first have to specify the natural language they are working with,
thanks to the
langid attribute.
A grammar file can contain several RULE,
which can be accessed from other rules with RULEREF or be active from the beginning
thanks to TOPLEVEL="ACTIVE".
All the words or sentences to be recognized are stored in containers like PHRASE or LIST.
In a PHRASE container, all the sub-elements are to be recognized sequentially,
whereas in a LIST container, only one of the sub-elements will be matched.
The OPT container makes its content to be optionally part of the grammar.
The PN and LN containers are respectively similar to PHRASE and LIST,
except that they return the value specified in their VAL attribute, instead of the plain text.
| SYM | IPA Unicode | Example | PhoneID |
|---|
| - | 002D | syllable boundary (hyphen) | 1 |
| ! | 0021 | Sentence terminator (exclamation mark) | 2 |
| & | 0023,0020 | word boundary | 3 |
| , | 002C | Sentence terminator (comma) | 4 |
| . | 002E | Sentence terminator (period) | 5 |
| ? | 003F | Sentence terminator (question mark) | 6 |
| _ | 005F | Silence (underscore) | 7 |
| 1 | 02C8 | Primary stress | 8 |
| 2 | 02CC | Secondary stress | 9 |
| aa | 0251 | father | 10 |
| ae | 00E6 | cat | 11 |
| ah | 028C | cut | 12 |
| ao | 0254 | dog | 13 |
| aw | 0251+028A | foul | 14 |
| ax | 0259 | ago | 15 |
| ay | 0251+026A | bite | 16 |
| b | 0062 | big | 17 |
| ch | 0074+0283 | chin | 18 |
| d | 0064 | dig | 19 |
| dh | 00F0 | then | 20 |
| eh | 025B | pet | 21 |
| er | 025A | fur | 22 |
| ey | 0065 | ate | 23 |
| f | 0066 | fork | 24 |
| g | 0067 | gut | 25 |
| h | 0068 | help | 26 |
| ih | 026A | fill | 27 |
| iy | 0069 | feel | 28 |
| jh | 02A4 | joy | 29 |
| k | 006B | cut | 30 |
| l | 006C | lid | 31 |
| m | 006D | mat | 32 |
| n | 006E | no | 33 |
| ng | 014B | sing | 34 |
| ow | 006F | go | 35 |
| oy | 0254+026A | toy | 36 |
| p | 0070 | put | 37 |
| r | 0279 | red | 38 |
| s | 0073 | sit | 39 |
| sh | 0283 | she | 40 |
| t | 0074 | talk | 41 |
| th | 03B8 | thin | 42 |
| uh | 028A | book | 43 |
| uw | 0075 | too | 44 |
| v | 0076 | vat | 45 |
| w | 0077 | with | 46 |
| y | 006A | yard | 47 |
| z | 007A | zap | 48 |
| zh | 0292 | pleasure | 49 |
This grammar is made to recognize real words,
and cannot be used directly to recognize sounds or acronyms.
Nevertheless, there is a possibility to do that with phonetics.
A PHRASE container, for example, can have a PRON attribute that specify how to pronounce
what is inside this container, and which will be used by the speech engine instead of the plain text.
For example, "h eh - l ow 1" phonetically codes for "Hello".
I have reproduced, here on the left, the
American English phoneme representation
since it is not easy to find, and the Web page does not seem to be maintained anymore.
A grammar example is provided bellow.
Conclusion
This Microsoft Sapi 5 development kit provides a fast and efficient solution
for integrating voice technologies to a project.
This solution has been chosen for developing all the needed programs that were not based on Nuance.
Nuance 8.0
Introduction
Nuance 8.0
is a professional voice recognition and synthesizes suite provided by the eponym Californian company.
A trial version of Nuance 8.0 has finally been received on the 10th of June 2003.
This will be the recognition system used for demos and other tests,
in order to be coherent with other partners of the SafeSound project.
Installation
The nuance installation has to be done, just by running the setup.
Then it is a good choice to install the grammar builder.
Since Nuance is a client/server solution, the server has to be started before the client.
First of all, the Nuance License Manager has to be launched,
with the license key as parameter.
C:\nuance\test1>nlm ntk8-800-a-x46-????????????
SN: 800
HostLock: anyhost
Port: 8470
Checksum: bfba85334e02
1/ 1 server 800 899 1-jan-2038
2/ 2 sp-chan 800 899 1-jan-2038
2/ 2 v-chan 800 899 1-jan-2038
1/ 1 tool 800 899 1-jan-2038
Nuance License Manager ready.
The second step is for the server.
It is the one that makes the recording, the recognition and gives the client the results as text tokens.
It has to be called with the grammar to be used in parameter (-package [path of grammar folder]).
C:\nuance\test1>recserver -package fruit lm.Addresses=localhost
Nuance Recognition Server
All debug information is currently logged into ./logs/recserver_log_current
Finally the client can be launched, specifying also the grammar, and other configuration parameters.
Here is an example chosen from application 1.2,
when the user says "Navigation display L S", with an output of the accessible information from the server.
C:\nuance\test>java -classpath "classes" nuancend.NuanceApplication -package nuance/ND
lm.Addresses=localhost audio.Provider=native client.NoSpeechTimeoutSecs=10 client.AllowBargeIn=FALSE
audio.InputVolume=255 audio.OutputVolume=255
---------- Recognition started ----------
Wait for input
dtype=17
type=RECOGNITION
results=[{
dtype=10
text="navigation display l s"
probability=-7942
confidence=56
confidenceWithoutFiller=50
wordConfidences=[67,51,21,62]
interp=[{
dtype=9
probability=0
slotValue={
sViewMode="ILS"
}
slotInfo={
sViewMode={
allWordConfidence=0
necessaryWordConfidence=0
}
}
}]
}]
textRecresult=
numFrames=233
firstPassRecognizerInfo=
secondPassRecognizerInfo=Male
sViewMode=ILS
Wait for input
...
Programming
The development of a voice recognition application always starts by preparing the grammar.
This can be done in Nuance with the help of the Grammar Builder environment.
It provides some tools for editing and testing the grammar,
like a library of existing grammars in several languages,
and a generator of possible sentences.
The Nuance Grammar Builder main window.
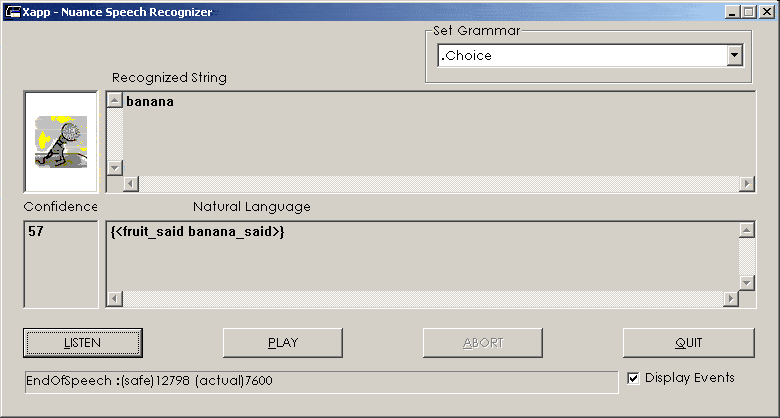
After the grammar tested in text mode, it can be tested with a speech interface.
Xapp is a small program that can work with any Nuance's grammar and will show what could have been understood,
according to the grammar.
The Xapp application running with a test grammar about fruits
Conclusion
With its client/server architecture, Nuance provides a fast solution for building voice recognition applications.
It has some good assets, like the possibility to access to the list of the n-best choices after recognition,
which is a requirement for the SafeSound project.
Nevertheless, Nuance seems to be quite orientated on telephony projects,
and it is a heavy solution to make small programs with an integrated voice recognition system
that have to be distributed to several clients.
Application 1: Navigation display
Introduction
The aim of this demo is to demonstrate how a pilot could control the navigation display with voice.
There are different display modes, which can be seen at different ranges.
I will just describe the theoretical speech part of this demo,
which uses Microsoft Sapi 5.0.
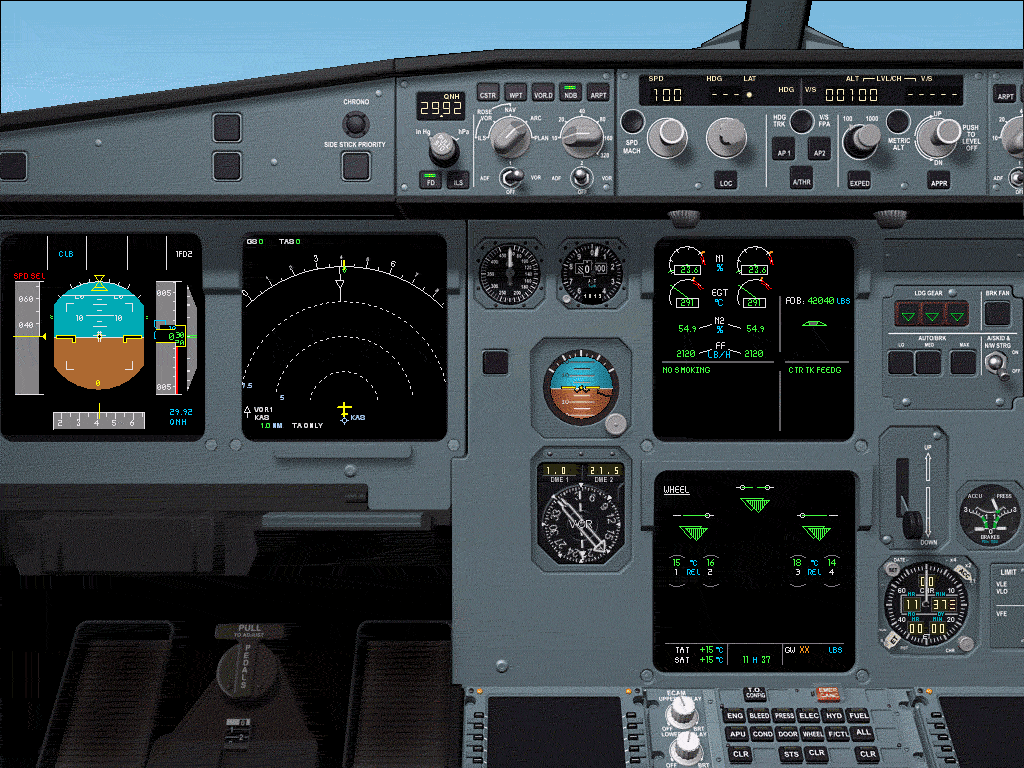
The navigation display
The navigation display shows the pilot a blank map with his flight plan shown as a line between way points.
Five different display modes with six ranges can be shown.
Additional information can be provided as well, like the TCAST collision avoidance system.
Grammar
A Microsoft Sapi 5 grammar had to be defined for this application.
It can recognize commands to change the kind of display, which can be followed by the range of the display:
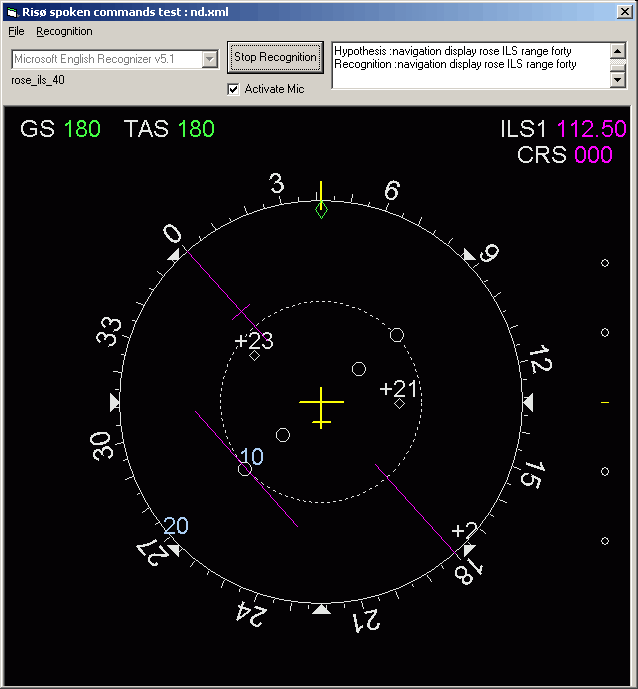
(navigation)? display (arc|plan|rose ils|rose nav|rose vor) ((range)? (10|20|40|80|160|320))?
It can also recognize commands to change just the range, keeping the same kind of display:
(navigation)? display range (10|20|40|80|160|320)
nd.xml
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
<!-- SAPI 5.0 SR Command and Control grammar -->
<!-- xml:lang="en-US" -->
<!-- Risø spoken commands test -->
<GRAMMAR LANGID="409">
<DEFINE><!-- Constants definitions for PROPID -->
<ID NAME="ARC" VAL="1"/>
<ID NAME="PLAN" VAL="2"/>
<ID NAME="ROSE" VAL="3"/>
<ID NAME="RANGE" VAL="9"/>
<ID NAME="ILS" VAL="301"/>
<ID NAME="NAV" VAL="302"/>
<ID NAME="VOR" VAL="303"/>
<ID NAME="NUMB" VAL="9"/>
</DEFINE>
<RULE NAME="rulend" TOPLEVEL="ACTIVE"><!-- Main rule -->
<PHRASE>
<OPT>navigation</OPT><!-- Optional introduction word -->
<PHRASE>display</PHRASE><!-- Introduction word -->
<LIST><!-- List of choices of commands -->
<PHRASE PROPNAME="arc"><!-- ARC display -->
<PHRASE>arc</PHRASE>
<!-- Call rule "rulerange" -->
<RULEREF PROPNAME="rulerange" PROPID="RANGE" NAME="rulerange"/>
</PHRASE>
<PHRASE PROPNAME="plan"><!-- PLAN display -->
<PHRASE>plan</PHRASE>
<!-- Call rule "rulerange" -->
<RULEREF PROPNAME="rulerange" PROPID="RANGE" NAME="rulerange"/>
</PHRASE>
<PHRASE>
<PHRASE>rose</PHRASE><!-- ROSE display -->
<!-- Call rule "rulerose" -->
<RULEREF PROPNAME="rose" PROPID="ROSE" NAME="rulerose"/>
</PHRASE>
<PHRASE>
<PHRASE>range</PHRASE><!-- Just change the range -->
<!-- Call rule "rulenumb" -->
<RULEREF PROPNAME="range" PROPID="RANGE" NAME="rulenumb"/>
</PHRASE>
</LIST>
</PHRASE>
</RULE>
<RULE NAME="rulerose"><!-- Rule to recognise the different ROSE displays -->
<LIST><!-- List of choices of displays -->
<PHRASE PROPNAME="ils"><!-- ROSE ILS display -->
<PHRASE PRON="ay eh l eh s">ILS</PHRASE><!-- ILS is explained phonetically -->
<!-- Call rule "rulerange" -->
<RULEREF PROPNAME="rulerange" PROPID="RANGE" NAME="rulerange"/>
</PHRASE>
<PHRASE PROPNAME="nav"><!-- ROSE NAV display -->
<PHRASE>nav</PHRASE>
<!-- Call rule "rulerange" -->
<RULEREF PROPNAME="rulerange" PROPID="RANGE" NAME="rulerange"/>
</PHRASE>
<PHRASE PROPNAME="vor"><!-- ROSE VOR display -->
<PHRASE>vor</PHRASE>
<!-- Call rule "rulerange" -->
<RULEREF PROPNAME="rulerange" PROPID="RANGE" NAME="rulerange"/>
</PHRASE>
</LIST>
</RULE>
<RULE NAME="rulerange"><!-- Rule to recognise an optional range definition -->
<OPT><!-- The whole rule is optional -->
<OPT><!-- Optional introduction word -->
<PHRASE>range</PHRASE>
</OPT>
<!-- Call rule "rulenumb" -->
<RULEREF PROPNAME="range" PROPID="RANGE" NAME="rulenumb"/>
</OPT>
</RULE>
<RULE NAME="rulenumb"><!-- Rule to recognise numbers for the range -->
<LN PROPNAME="numb" PROPID="NUMB">
<PN VAL="10">ten</PN>
<PN VAL="10">one zero</PN>
<PN VAL="10">one oh</PN>
<PN VAL="20">twenty</PN>
<PN VAL="20">two zero</PN>
<PN VAL="40">forty</PN>
<PN VAL="40">four zero</PN>
<PN VAL="80">eighty</PN>
<PN VAL="80">eight zero</PN>
<PN VAL="160">one six zero</PN>
<PN VAL="320">three two zero</PN>
</LN>
</RULE>
</GRAMMAR>
Programming
Voice recognition has been added to an existing demo, written in Visual Basic.
Here is a peace of the code, which intercepts the recognition events thrown by the voice engine.
This occurs when a grammar rule has been correctly and completely recognized.
(Lots of other events are thrown, for each step of the grammar, hypothesis, false recognitions, etc.)
RecoVB.frm
Private Sub RC_Recognition(ByVal StreamNumber As Long, ByVal StreamPosition As Variant,
ByVal RecognitionType As SpeechLib.SpeechRecognitionType,
ByVal Result As SpeechLib.ISpeechRecoResult)
Dim RecoNode As Node
Dim Prop As ISpeechPhraseProperty
Dim Prop2 As ISpeechPhraseProperty
'Update Event List window
UpdateEventList StreamNumber, StreamPosition,
"Recognition", " :" & Result.PhraseInfo.GetText()
Set Prop = Result.PhraseInfo.Properties(0)
If Not Prop Is Nothing Then
If Prop.Name = "range" Then 'change just the range
Set Prop = Prop.Children.Item(0)
If Not Prop.Value = Empty Then
RangeValue = Prop.Value
End If
Else 'change the display
ModeName = Prop.Name
If ModeName = "rose" Then 'special case for rose display
If Not Prop.Children Is Nothing Then
Set Prop2 = Prop.Children.Item(0)
ModeName = ModeName & "_" & Prop2.Name
Set Prop = Prop.Children.Item(1) 'change also the range
If Not Prop Is Nothing Then
If Prop.Name = "rulerange" And Not Prop.Children Is Nothing Then
Set Prop = Prop.Children.Item(0)
If Prop.Name = "range" Then
Set Prop = Prop.Children.Item(0)
If Not Prop Is Nothing And Not Prop.Value = Empty Then
RangeValue = Prop.Value
End If
End If
End If
End If
End If
Else
Set Prop = Result.PhraseInfo.Properties(1)
If Not Prop Is Nothing Then 'change also the range
If Prop.Name = "rulerange" And Not Prop.Children Is Nothing Then
Set Prop = Prop.Children.Item(0)
If Prop.Name = "range" Then
Set Prop = Prop.Children.Item(0)
If Not Prop Is Nothing And Not Prop.Value = Empty Then
RangeValue = Prop.Value
End If
End If
End If
End If
End If
End If
End If
LabelPicture.Caption = BuildDisplayName(ModeName, RangeValue)
Picture1.Picture = LoadPicture(BuildDisplayPath(ModeName, RangeValue))
'Save the recognition Result to the global RecoResult
Set RecoResult = Result
End Sub
This demonstration was fully functional and could be used for some tests.
Application 1.2: Navigation display
Introduction
This navigation display demo is the same as the one made with Sapi,
except that it is made using Nuance 8.0
and written in Java.
It is also providing extra functionalities.
The navigation display, just been changed to the ROSE ILS mode.
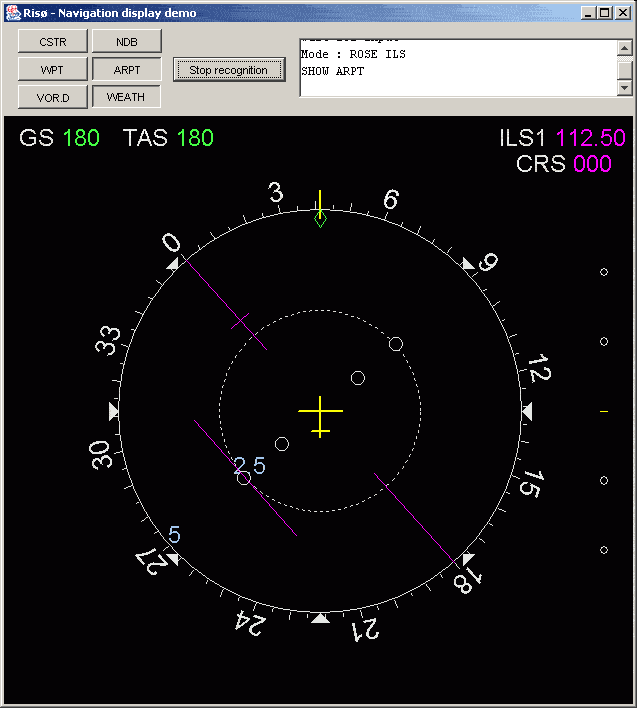
Grammar
The Nuance grammar used in this demo was made by
TNO (NL),
a partner in this project.
I think this grammar was not restrictive enough to be used in a safety critical domain,
and it was not made with interaction enough with real pilots.
It as been studied in order to build the program, and to provide a list of some possible sentences.
After a meeting, and thanks to this prototype that have been tested by pilots,
it as been planed to modify this grammar according to these remarks.
Programming
Java has been used for this demo.
The java libraries provided by nuance have been useful to connect to the server,
to receive and parse its answers.
Here is a sample from this demo, which shows most of the needed code for building a simple Nuance client.
//Create a NuanceConfig object from the command-line arguments
NuanceConfig config = new NuanceConfig();
String[] extra_args = config.buildFromCommandLine(args);
//Create the SpeechChannel object
nsc = new NuanceSpeechChannel(config);
while (recognition)
{
/* ... more code was here ... */
if ((rec_result.getNumResults() > 0) &&
(rec_result.getSingleResult(0).getNumInterpretations() > 0))
{ // Check the returned recognition result.
// There is at least one result with one interpretation
SingleResult sr = rec_result.getSingleResult(0);
KVSet slots = sr.getInterpretation(0).getSlots();
if (slots.keyExists(VIEW_MODE)) //returns a text token specifying the mode
{ //change the mode of the navigation display
String mode_chosen = slots.getString(VIEW_MODE);
if (mode_chosen.equals(VIEWMODE_ILS)) currentMode="ROSE_ILS";
else if (mode_chosen.equals(VIEWMODE_VOR)) currentMode="ROSE_VOR";
/* ... more code was here ... */
else appendText("An unrecognised view mode was said");
}
if (slots.keyExists(RANGE_SELECT)) //returns an integer token specifying the range
{ //change the range of the navigation display
int range_chosen = slots.getInt(RANGE_SELECT);
appendText("Range "+range_chosen);
currentRange = range_chosen;
}
/* ... more code was here ... */
}
else //NO_SPEECH_TIMEOUT or similar
{
appendText("Nothing intelligible was said");
}
}
if (nsc != null) nsc.close(); //Close the SpeechChannel
Application 2: Radio Mode Panel
Introduction
The aim of this demo is to demonstrate how a pilot could control the Radio Mode Panel with voice.
The radio mode panel
The radio mode panel (RMP) controls the frequency of the three
VHF and
two HF radios in the cockpit.
Basic operation is that the pilot changes the frequency of the standby display by turning a button
and when he is satisfied he can activate this frequency by switching the active frequency with the standby one.
Each pilot has a RMP and a third one is located in the over-head panel.
All the five radios can be remoted from any of the three panels.
The Radio Mode Panel demo.
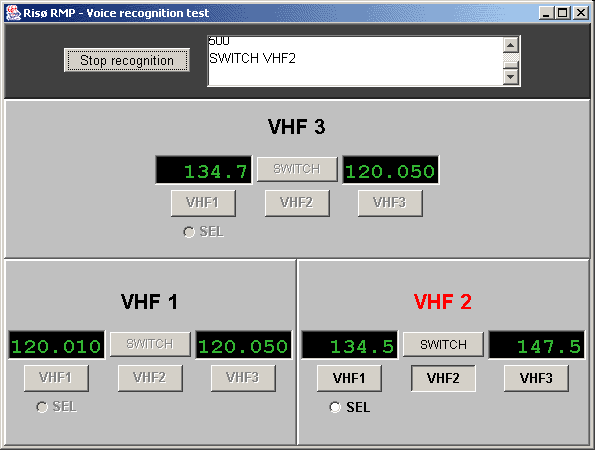
Grammar
The Nuance grammar used in this demo was also made by TNO.
Multi-modal Web browser
This is my secondary and more personal project, about Web pages accessibility standards,
and a system that allows voice input commands in a Web browser.
You can read my separated report on this multi-modal Web browser project.
Conclusion
The two applications I have made were demonstrated at a meeting in Rome for Alitalia pilots.
They have been useful to test some concepts and the grammars.
Thanks to these demos, pilots have been involved into the project and give their opinion.
During these six months, I have had the opportunity to test and program several speech engines
and I am now more able to chose a speech engine, according to the needs of any project.
Furthermore, I have largely improved my knowledge about Internet standards and accessibility,
and I am now more familiar with plug-in integration in Mozilla.
Last but not the least, I have been in touch with safety critical domains,
and worked with cross-disciplinary scientists with cultures different from the French one;
that gave new outlets to my competences.
This traineeship has been a good opportunity for me to discover another culture
and that is almost as important as the scientific experience. I am now able to have small conversations in Danish,
and I have even started to read small articles in newspapers.
I have been very pleased to do this traineeship in Risø and it was a wonderful experience.
So it was with pleasure that I have accepted the PhD proposition.

Risø large view from a plane
About this document
The content of this document has been written
conforming to XHTML 1.1 (05/2001),
current best choice standard for Web pages, which allows a backward compatibility with old
HTML browsers,
having all the advantages of being valid XML 1.0 (02/1998),
and is viewable on light systems like mobiles phones.
CSS2 (12/1998) style sheets are used for the presentation;
that could allow different viewing on computer screen, projectors, handheld, printers, etc. or for impaired people.
The character set of this document is UTF-8 (1993),
which is backward compatible with the 128 first basic ASCII characters (1963),
whereas all the other Unicode
characters can be also coded (on two or more bytes); it is the most widely used Unicode character set on the Web (since 1997),
and the default one for XML (1996).
This page respects the conformance
level A of the W3C Web Content Accessibility Guidelines 1.0,
which promotes accessibility for people with disabilities and more generally to all users,
whatever browser and constraints they may have.
The aim is also to help people to find information on the Web more quickly
and make multimedia content more accessible to a wide audience.
This document provides some metadata information according to
"The Dublin Core Metadata Initiative" (1995),
which is an organization dedicated to fostering the widespread adoption of interoperable metadata standards
for describing resources to enable more intelligent resource discovery systems.
Other HTML META and LINK tags are used for standard navigation (top, search, toc, help, etc.) and other information (location, ...).
More technical information can be found on my headers and META information in HTML documentation page.
The choice of these standards, recommended by the W3C,
confers to this document one of the largest possible "viewability", prepared for the future.
The backward compatibility is good, even with text browsers, but a nicer result, with more functionalities will be achieved with
recent standard compliant browsers (Mozilla 1.4, Opera 7 are fine;
Internet Explorer 6 is okay but do not provide standard navigation nor CSS2 conformance.).
This document is still under construction.
The final version is aimed to match all these standards even better,
especially about accessibility.




You can also have a look to the "about page" of this Web site.
Exit