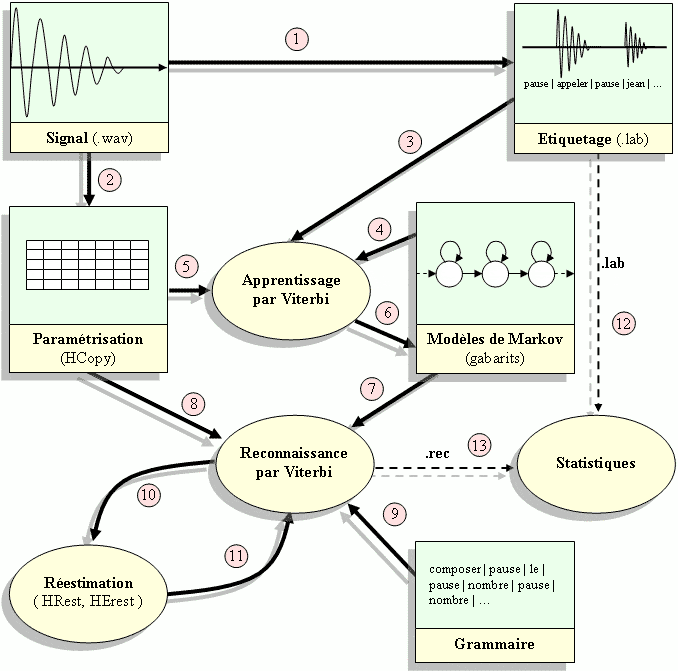
Le but est de construire un système de reconnaissance de mots isolés
et de le valider sous l'environnement HTK (Hidden Markov Model Toolkit).
Le système à réaliser sera un composeur téléphonique,
qui sera capable de reconnaître à la fois les commandes de composition de numéros téléphoniques
mais aussi les commandes d'appel d'une personne connue du système.
Différentes étapes sont nécessaires à la construction et à la validation du système.
Voici un schéma global du système de reconnaissance utilisé :
Pour l'apprentissage, Viterbi utilise :
Pour la reconnaissance, Viterbi utilise :
Une réestimation peut être faite par HRest et HErest
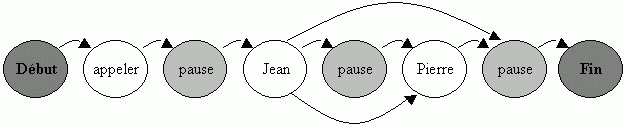
Le modèle de langage est un réseau d'éléments lexicaux qui décrit la façon dont ils s'enchaînent dans les phrases.
Exemple : voici le réseau qui permet de générer les phrases "appeler Jean" et "appeler Jean Pierre".
Pour obtenir "un bon apprentissage", les systèmes à base de modèles de Markov nécessitent beaucoup de données.
On va donc limiter le nombre de chiffres à reconnaître,
ce qui permettra de se contenter d'un corpus monolocuteur restreint.
Afin d'homogénéiser les fichiers de tout le monde, on va fixer l'énoncer des phrases à enregistrer.
On a enregistré sous Linux avec le logiciel "WaveSurfer".
Il est apparu que les fichiers enregistrés étaient très bruités,
et ce surtout à cause de parasites au niveau du microphone
et des connections audio, mais aussi à cause du bruit ambiant (reste de la classe).
On a normalisé les fichiers afin de recadrer un peu la dynamique.
Nous avons aussi supprimé quelques bruits trop gênants.
Le but de l'étiquetage est de délimiter chaque entité lexicale. Ceci sera fait manuellement avec le logiciel HSLab.
Nous avons fait cette opération, parfois avec l'aide de "WaveSurfer".
Ci-dessous, un exemple de fichier résultat (2003-03composerle4651320.lab),
où l'on voit le nom de l'étiquette, l'indice de départ, et l'indice de fin.
Il n'est pas très grave que des étiquettes se chevauchent un peut,
ou ne soient pas jointées.
121250 4307500 pause 4316875 10478125 composer 10468750 13980625 pause 13990000 16680000 le 16670625 21691250 pause 21700625 24928750 quatre 24919375 29339375 pause 29348750 33590000 six 33580625 37296875 pause 37306250 41116875 cinq 41107500 47015000 pause 47025000 48726875 un 48717500 54275625 pause 54285000 57360625 trois 57351250 64190625 pause 64190625 65928750 deux 65919375 71282500 pause 71291875 74215625 zero 74205625 83361250 pause
Après avoir acquis les fichiers sons, on construira une représentation acoustique du signal.
On appellera la commande Hcopy pour copier les fichiers contenants les cepstraux.
Hcopy -T 1 -C Config/parametrisation.conf -S Listes/hcopy.txt./parametrisation Listes/hcopy.all.lstPour chaque entité lexicale, on définira le modèle associé. Pour cela, on donnera la topologie de chaque modèle, le nombre d'états et les probabilités de transition entre les états.
Nous avons d'abord transcrit les mots en phonétique, par-dessus laquelle nous avons essayé de construire un modèle de Markov. Notez que nous avons divisé en deux états les consonnes explosives "P, t, k, b, d, g".
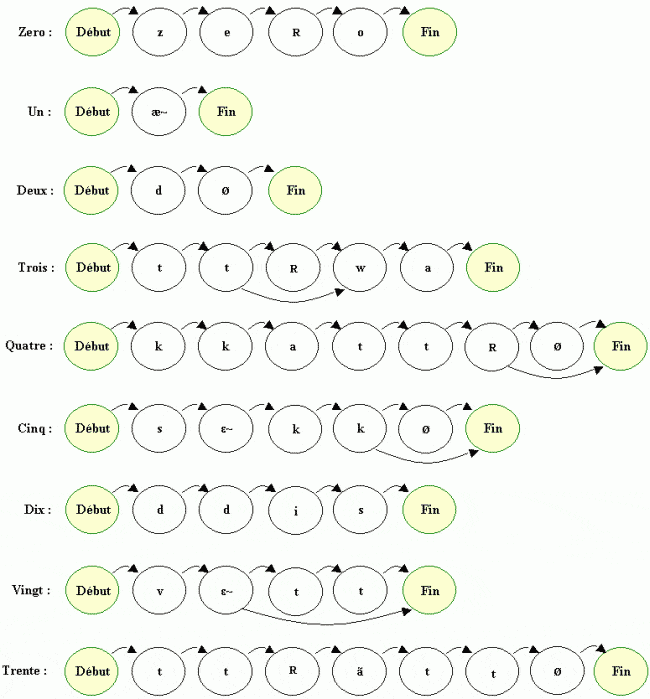
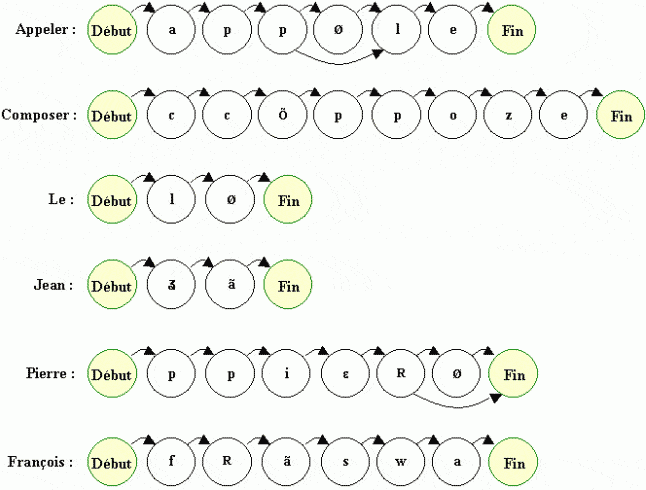
Les flèches représentent les transitions entre états.
On voit bien sur "quatre" la possibilité de sauter un état,
selon si l'on prononce ou pas le "e" final de "quatre".
Notez que nous avons encore effectué de légères modifications lors de la création des fichiers gabarits,
afin de mieux prendre en compte les différentes prononciations,
ou encore les raccourcis dus à une élocution rapide :
ainsi "quatre" peut devenir "quatt" (on rajoute pour cela une probabilité de transition entre l'état "t" et l'état final.
Nous n'avons pas à calculer les lignes correspondant à la moyenne et à la variance, ce sera fait de manière automatique dans la prochaine partie. Nous reportons le nombre d'états de nos modèles de Markov, ainsi que les probabilités de transition entre les états. Il est ajouté un état de début et un état de fin.
Dans la partie "<TransP>", chaque ligne correspond à un état,
et les différentes colonnes aux probabilités de transition vers un des autres états.
Notons qu'il n'y a jamais de possibilité (probabilité > 0) vers des états précédents.
On peut voir sur la 1ère ligne, 2ème colonne,
que nous avons mis une probabilité de 1 pour passer de l'état de départ à l'état 1.
Il faut voir que les états du modèle de Markov ne correspondent pas forcément aux différents phonèmes du mot,
mais les phonèmes nous ont aidés pour le concevoir.
Exemple de fichier gabarit pour "six" :
<BeginHMM>
<NumStates> 5 <VecSize> 26 <MFCC_D_E> <diagC>
<State> 2
<Mean> 26
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<Variance> 26
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<State> 3
<Mean> 26
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<Variance> 26
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<State> 4
<Mean> 26
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<Variance> 26
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<TransP> 5
0.000e+0 1.000e+0 0.000e+0 0.000e+0 0.000e+0
0.000e+0 9.000e-1 1.000e-1 0.000e+0 0.000e+0
0.000e+0 0.000e+0 9.000e-1 1.000e-1 0.000e+0
0.000e+0 0.000e+0 0.000e+0 9.000e-1 1.000e-1
0.000e+0 0.000e+0 0.000e+0 0.000e+0 0.000e+0
<EndHMM>
Chaque modèle doit être appris : les moyennes, les variances et les probabilités de transition entre états sont réestimées jusqu'à ce qu'un seuil de convergence ou qu'un nombre maximum d'itération soient atteint. Ceci est fait par l'algorithme de Viterbi.
On utilise des scripts prédéfinis en leur passant la liste des modèles devant être appris.
Les modèles sont ensuite réestimés de façon indépendante de façon indépendante avec l'algorithme de Baum-Welch,
en utilisant un script prédéfini à base du programme Hrest.
On peut ensuite améliorer l'apprentissage avec un autre script à base du programme HErest,
qui utilise l'algorithme de Baum-Welch pour réestimer tous les modèles à la fois.
Hrest utilise une paramétrisation de type MFCC (Mel-scaled FFT based cepstrum), qui se réalise en plusieurs étapes :
L'algorithme de Baum-Welch est de type réestimation itératif. Il est associé aux états, aux transitions et aux symboles le nombre de fois où ils sont utilisés pour toutes les séquences et tous les chemins susceptibles de générer les séquences, pondéré par la probabilité du chemin.
La reconnaissance se fait avec l'algorithme de Viterbi qui, dans l'environnement HTK,
nécessite l'utilisation de diverses connaissances : les modèles HMM, le modèle de langage, et le dictionnaire.
Le modèle de langage est généré par la fonction HParse à partir de la description du réseau dans un fichier texte.
L'algorithme de Viterbi :
Nous avons un peu modifié les exemples de modèle de grammaire fourni, pour l'apprentissage et la reconnaissance, de manière à ce qu'il intègre tous les chiffres utilisés :
$chiff = zero | un |deux | trois | quatre | cinq | six | dix | vingt | trente;
$pause = pause ;
$prenom = [ jean [pause] ] pierre | jean | [ jean [pause] ] francois ;
$numerotel = $chiff [$pause] $chiff [$pause] $chiff [$pause] $chiff [$pause] $chiff [$pause] $chiff [$pause] $chiff ;
( SENT-START
( $pause ( composer | appeler ) [$pause] le [$pause] $numerotel [$pause] )
| ( < $pause appeler [$pause] $prenom > [$pause] )
SENT-END )
La reconnaissance sera ensuite effectuée sur chaque fichier en utilisant successivement les modèles issus de HInit,
HRest, puis HERest (afin d'évaluer l'apport des divers apprentissages).
Pour cela, on appellera le script prédéfini à base du programme Hvite.
Le script utilise un modèle de mots (représentation interne de la grammaire de mots),
et un dictionnaire (correspondance entre les labels et les mots à trouver au niveau de la reconnaissance.
Ces trois méthodes donnent des résultats différents, et dans notre cas, HErest s'est souvent montré le meilleur pour la reconnaissance de mots isolés, tandis que HInit donnait de meilleur scores de reconnaissance des phrases.
Des fichiers sont alors générés, avec la liste des mots reconnus, le départ et la fin de ces mot dans le fichier,
ainsi qu'un score.
Exemple : début du fichier de résultat pour la reconnaissance (base et reconnaissance IRR03 2003)
sur le fichier "appeler1".
0 14300000 pause -6574.211426 14300000 20700000 appeler -3206.063721 20700000 26700000 pause -2626.228027 26700000 29600000 jean -1588.385742 29600000 42600000 pause -5647.290527 42600000 48000000 appeler -2530.219971 48000000 54900000 pause -2998.869141 54900000 61100000 pierre -2742.406250 61100000 73300000 pause -5221.282227
L'évaluation des résultats peut se faire automatiquement avec la fonction HResult,
qui utilise les résultats de HInit, HRest ou HERest.
On pourra aussi utiliser un des scripts resultats*.
HResult accepte différents paramètres.
Avec HResult -z pause, nous avons essayé de ne pas prendre en compte les pauses dans le calcul des taux.
Les résultats donnés par le script resultat3 sont de la forme :
Afin de respecter les règles classiques d'un système de reconnaissance,
nous faisons un apprentissage sur toute la base 2001, et une reconnaissance sur toute la base 2002,
ainsi, les fichiers à reconnaître ne sont pas utilisés pendant l'apprentissage,
ce qui biaise la qualité des résultats.
Les fichiers à reconnaître étant eux aussi étiquetés,
il est possible de mesurer par comparaison la qualité du système de reconnaissance,
qualité exprimée ci-dessous :
HInit
------------------------ Overall Results --------------------------
SENT: %Correct=8.70 [H=6, S=63, N=69]
WORD: %Corr=92.75, Acc=82.32 [H=1280, D=21, S=79, I=144, N=1380]
------------------------ Confusion Matrix -------------------------
a c c d f j p p q s t u l z d v t
p i o e r e a i u i r n e e i i r
p n m u a a u e a x o r x n e
e q p x n n s r t i o g n
l o c e r r s t t Del [ %c / %e]
appe 109 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 [99.1/0.1]
cinq 0 39 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
comp 0 0 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
deux 0 2 0 33 0 0 1 0 1 0 0 0 0 1 1 0 0 1 [84.6/0.4]
fran 0 0 0 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0
jean 0 0 0 0 0 59 0 1 0 0 0 0 0 0 0 0 0 0 [98.3/0.1]
paus 1 0 0 0 0 0 681 0 4 1 0 0 1 0 0 0 0 12 [99.0/0.5]
pier 0 0 0 0 0 3 1 36 0 0 0 0 0 0 0 0 0 0 [90.0/0.3]
quat 0 3 0 0 0 0 0 0 35 0 1 0 0 0 0 0 1 0 [87.5/0.4]
six 0 1 0 0 0 0 0 0 0 29 0 0 0 0 9 0 0 1 [74.4/0.7]
troi 0 0 0 0 0 0 0 0 0 0 37 0 0 0 0 0 3 0 [92.5/0.2]
un 0 8 0 2 0 0 0 0 3 0 0 18 0 0 0 2 3 3 [50.0/1.3]
le 0 0 0 0 0 0 0 0 0 0 0 0 40 0 0 0 0 0
zero 0 0 0 0 0 0 0 0 0 0 0 0 0 40 0 0 0 0
dix 5 1 2 0 0 0 0 0 0 0 0 0 0 0 17 0 0 2 [68.0/0.6]
ving 0 3 1 1 0 0 0 0 2 0 0 0 7 0 0 12 1 0 [44.4/1.1]
tren 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 25 1 [96.2/0.1]
Ins 32 0 0 0 2 39 66 1 1 1 0 0 1 0 1 0 0
===================================================================
HRest
------------------------ Overall Results --------------------------
SENT: %Correct=4.35 [H=3, S=66, N=69]
WORD: %Corr=92.97, Acc=82.97 [H=1283, D=16, S=81, I=138, N=1380]
------------------------ Confusion Matrix -------------------------
a c c d f j p p q s t u l z d v t
p i o e r e a i u i r n e e i i r
p n m u a a u e a x o r x n e
e q p x n n s r t i o g n
l o c e r r s t t Del [ %c / %e]
appe 109 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 [99.1/0.1]
cinq 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
comp 0 0 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
deux 0 0 0 34 0 0 1 0 1 0 0 0 0 2 1 0 0 1 [87.2/0.4]
fran 0 0 0 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0
jean 0 0 0 0 0 59 0 1 0 0 0 0 0 0 0 0 0 0 [98.3/0.1]
paus 1 0 0 0 0 0 687 0 2 0 0 0 0 0 1 0 0 9 [99.4/0.3]
pier 0 0 0 0 0 2 1 37 0 0 0 0 0 0 0 0 0 0 [92.5/0.2]
quat 0 2 0 0 0 0 0 0 36 0 0 0 0 1 0 0 1 0 [90.0/0.3]
six 0 1 0 0 0 0 0 0 0 26 0 0 0 0 12 0 0 1 [66.7/0.9]
troi 0 0 0 0 0 0 0 0 0 0 38 0 0 0 0 0 2 0 [95.0/0.1]
un 0 18 0 1 0 0 0 0 3 0 0 12 0 0 0 1 2 2 [32.4/1.8]
le 0 0 0 0 0 0 0 0 0 0 0 0 40 0 0 0 0 0
zero 0 0 0 0 0 0 0 0 0 0 0 0 0 39 0 0 0 1
dix 5 1 3 0 0 0 0 0 0 0 0 0 0 0 17 0 0 1 [65.4/0.7]
ving 0 4 0 0 0 0 0 0 1 0 0 0 8 0 0 13 1 0 [48.1/1.0]
tren 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 26 1
Ins 29 1 0 0 3 35 65 1 1 1 0 0 1 0 1 0 0
===================================================================
HErest
------------------------ Overall Results --------------------------
SENT: %Correct=5.80 [H=4, S=65, N=69]
WORD: %Corr=92.97, Acc=81.23 [H=1283, D=16, S=81, I=162, N=1380]
------------------------ Confusion Matrix -------------------------
a c c d f j p p q s t u l z d v t
p i o e r e a i u i r n e e i i r
p n m u a a u e a x o r x n e
e q p x n n s r t i o g n
l o c e r r s t t Del [ %c / %e]
appe 110 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
cinq 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
comp 0 0 30 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
deux 0 1 0 32 0 0 1 0 1 0 0 0 0 2 1 0 1 1 [82.1/0.5]
fran 0 0 0 0 40 0 0 0 0 0 0 0 0 0 0 0 0 0
jean 0 0 0 0 0 59 0 1 0 0 0 0 0 0 0 0 0 0 [98.3/0.1]
paus 0 0 0 0 0 0 687 0 2 0 0 0 0 0 0 0 0 11 [99.7/0.1]
pier 0 0 0 0 2 1 1 36 0 0 0 0 0 0 0 0 0 0 [90.0/0.3]
quat 0 2 0 0 0 0 0 0 35 0 2 0 0 1 0 0 0 0 [87.5/0.4]
six 0 1 0 0 0 0 0 0 0 29 0 0 0 0 10 0 0 0 [72.5/0.8]
troi 0 1 0 0 0 0 0 0 0 0 37 0 0 0 0 0 2 0 [92.5/0.2]
un 0 19 0 0 0 0 0 0 3 0 0 11 0 0 0 2 2 2 [29.7/1.9]
le 0 0 0 0 0 0 0 0 0 0 0 0 40 0 0 0 0 0
zero 0 0 0 0 0 0 0 0 0 0 0 0 0 39 0 0 0 1
dix 5 1 4 0 0 0 0 0 0 0 0 0 0 0 17 0 0 0 [63.0/0.7]
ving 0 2 0 0 0 0 0 0 1 0 0 0 8 0 0 15 1 0 [55.6/0.9]
tren 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 26 1
Ins 36 1 0 0 5 37 77 2 1 1 0 0 1 0 1 0 0
===================================================================
Sur l'ensemble des différents essais,
il y a en général une meilleure qualité d'assignation des mots avec HErest, puis HRest, HInit étant le moins bons.
Ici, cependant, le pourcentage de reconnaissance des phrases c'est avéré meilleur avec HInit.
Avec une base d'apprentissage constituée de tous les fichiers 2002,
et une reconnaissance sur la base 2003, les résultats sont moins bons.
Les fichiers de 2003 semblent en effet de moins bonne qualité (surtout due à du bruit semble-t-il).
Nous les avons limités à HErest.
HErest ------------------------ Overall Results -------------------------- SENT: %Correct=0.00 [H=0, S=63, N=63] WORD: %Corr=61.90, Acc=55.62 [H=788, D=193, S=292, I=80, N=1273] ===================================================================
Nous faisons à présent un apprentissage sur tous les sons de 2001 et 2002, et une reconnaissance sur tous ces sons aussi.
Il est clair que le fait d'utiliser la même base pour l'apprentissage et la reconnaissance biaise les résultats,
mais elle permet l'établissement d'une sorte de score d'auto-corrélation permettant de caractériser
la capacité du système de reconnaissance à utiliser correctement la variance des fichiers de sa base d'apprentissage.
Les résultats sont ceux de HErest car ce sont les meilleurs.
HErest
------------------------ Overall Results --------------------------
SENT: %Correct=6.47 [H=9, S=130, N=139]
WORD: %Corr=92.25, Acc=84.46 [H=2570, D=68, S=148, I=217, N=2786]
------------------------ Confusion Matrix -------------------------
a c c d f j p p q s t u l z d v t
p i o e r e a i u i r n e e i i r
p n m u a a u e a x o r x n e
e q p x n n s r t i o g n
l o c e r r s t t Del [ %c / %e]
appe 220 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
cinq 0 77 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 2 [98.7/0.0]
comp 0 0 60 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
deux 0 0 0 77 0 0 0 0 0 0 0 1 0 1 1 0 0 0 [96.2/0.1]
fran 0 0 0 0 79 0 0 0 0 0 0 0 0 0 0 0 0 1
jean 0 0 0 0 0 119 0 1 0 0 0 0 0 0 0 0 0 0 [99.2/0.0]
paus 0 0 0 0 0 0 1353 0 0 0 0 0 1 0 2 6 3 52 [99.1/0.4]
pier 0 0 0 0 0 1 0 79 0 0 0 0 0 0 0 0 0 0 [98.8/0.0]
quat 0 0 0 0 0 0 0 0 78 0 0 0 0 0 0 0 0 1
six 0 1 0 0 0 0 0 0 0 58 0 0 0 0 17 1 0 3 [75.3/0.7]
troi 0 0 0 0 0 0 0 0 0 0 77 0 0 0 0 0 0 3
un 0 19 0 1 0 0 1 0 6 0 0 5 0 0 0 39 6 2 [ 6.5/2.6]
le 0 0 0 0 0 0 0 0 0 0 0 0 80 0 0 0 0 0
zero 0 0 0 0 0 0 0 0 0 0 0 0 0 79 0 0 0 1
dix 7 0 11 0 0 0 0 0 0 0 0 0 1 0 38 0 0 0 [66.7/0.7]
ving 0 0 0 0 0 0 0 0 0 0 0 0 17 1 1 36 0 2 [65.5/0.7]
tren 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 55 1 [98.2/0.0]
Ins 43 0 0 0 5 54 107 3 1 2 0 0 0 1 0 1 0
===================================================================
L'apprentissage et la reconnaissance se font maintenant sur tous les sons de 2001, 2002 et 2003.
On constate une baisse de la qualité de reconnaissance, aussi bien au niveau phrase que mot.
Néanmoins, les erreurs sont mieux réparties sur les différents mots.
Ainsi, "un" avec 6.5% de reconnaissance sur le jeu d'essai 2001-2002 passe à 13.2% sur 2001-2002-2003.
HErest
------------------------ Overall Results --------------------------
SENT: %Correct=4.46 [H=9, S=193, N=202]
WORD: %Corr=90.05, Acc=81.30 [H=3655, D=134, S=270, I=355, N=4059]
------------------------ Confusion Matrix -------------------------
a c c d f j p p q s t u l z d v t
p i o e r e a i u i r n e e i i r
p n m u a a u e a x o r x n e
e q p x n n s r t i o g n
l o c e r r s t t Del [ %c / %e]
appe 316 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 [99.1/0.1]
cinq 0 109 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 6 [99.1/0.0]
comp 0 0 86 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 [98.9/0.0]
deux 1 4 0 87 0 0 0 0 1 0 0 0 0 3 6 3 9 2 [76.3/0.7]
fran 0 0 0 0 113 1 0 2 0 0 0 0 0 0 0 0 0 0 [97.4/0.1]
jean 0 0 0 0 1 170 0 3 0 0 0 0 0 0 0 0 0 0 [97.7/0.1]
paus 0 2 0 0 0 0 1950 0 1 0 0 0 0 1 5 10 4 94 [98.8/0.6]
pier 0 0 0 0 0 0 0 116 0 0 0 0 0 0 0 0 0 0
quat 0 0 0 0 0 1 0 0 109 0 0 0 0 0 0 2 0 3 [97.3/0.1]
six 1 1 0 1 0 0 0 0 1 72 0 0 0 0 28 1 4 7 [66.1/0.9]
troi 0 0 0 1 0 1 0 0 1 0 106 0 0 0 0 1 5 1 [92.2/0.2]
un 1 34 0 0 0 0 1 0 5 0 0 14 0 0 2 19 30 9 [13.2/2.3]
le 0 0 0 0 0 0 0 1 0 0 0 0 115 0 0 0 0 1 [99.1/0.0]
zero 0 1 0 0 0 1 0 0 0 0 0 0 0 109 0 1 2 2 [95.6/0.1]
dix 9 0 17 0 0 0 0 0 0 0 0 0 2 0 54 1 0 1 [65.1/0.7]
ving 0 1 0 0 0 0 0 0 0 0 1 0 25 1 0 52 2 2 [63.4/0.7]
tren 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 77 5 [97.5/0.0]
Ins 70 3 1 6 14 60 162 32 1 1 0 0 1 1 1 1 1
===================================================================
Il apparaît que "un" est très souvent confondu avec d'autres mots.
Il est souvent assigné à "cinq"(34), "trente"(30), "vingt"(19) et parfois à d'autres mots.
Nous avons essayé d'augmenter le nombre d'états du modèle de Markov de "un",
mais les résultats se sont montrés encore moins bons.
En monolocuteur avec la même base d'apprentissage et de reconnaissance groupe IRR03 en 2003
HInit
------------------------ Overall Results --------------------------
SENT: %Correct=57.14 [H=4, S=3, N=7]
WORD: %Corr=97.24, Acc=84.83 [H=141, D=4, S=0, I=18, N=145]
===================================================================
HRest
------------------------ Overall Results --------------------------
SENT: %Correct=71.43 [H=5, S=2, N=7]
WORD: %Corr=97.24, Acc=95.17 [H=141, D=4, S=0, I=3, N=145]
===================================================================
HErest
------------------------ Overall Results --------------------------
SENT: %Correct=71.43 [H=5, S=2, N=7]
WORD: %Corr=97.24, Acc=92.41 [H=141, D=4, S=0, I=7, N=145]
------------------------ Confusion Matrix -------------------------
a c c d f j p p q s t u l z d v t
p i o e r e a i u i r n e e i i r
p n m u a a u e a x o r x n e
e q p x n n s r t i o g n
l o c e r r s t t Del [ %c / %e]
appe 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
cinq 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
comp 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
deux 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0
fran 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0
jean 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0
paus 0 0 0 0 0 0 74 0 0 0 0 0 0 0 0 0 0 2
pier 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0
quat 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0
six 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0
troi 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0
un 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0
le 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0
zero 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0
dix 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 1
ving 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 1
tren 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0
Ins 2 0 0 0 0 2 2 0 0 0 0 0 1 0 0 0 0
===================================================================
Les résultats obtenus sont, comme prévus, nettement de meilleure qualité que sur du multilocuteur.
Un système monolocuteur donne normalement des résultats plus fiables,
et cela grâce à variance moindre des échantillons d'apprentissage, ce qui permet une meilleure modélisation,
et à une variance moindre des échantillons à reconnaître.
On évite aussi tous les problèmes liés aux variantes de prononciation.
Ici, les scores sont de plus biaisés, car vu la petitesse de notre base,
nous avons du utiliser tous les fichiers pour l'apprentissage, et donc tous les fichiers pour la reconnaissance.
A l'issue de ce BE, on peut voir qu'il existe des systèmes efficaces de reconnaissance.
Cependant, une certaine expertise des données à traiter est nécessaire,
de manière à choisir les meilleurs outils et paramètres.
Enfin, le système étudié est très sensible aux conditions d'enregistrement.
Cela a permis de bien appréhender les difficultés inhérentes à la mise en place d'un système de reconnaissance vocale.